🔍SAFE: Schema-Driven Approximate Distance Join for Efficient Knowledge Graph Querying
Lee, S., Park, S., Han, W.
EMNLP main track, Suzhou, China, November 2025.
▾
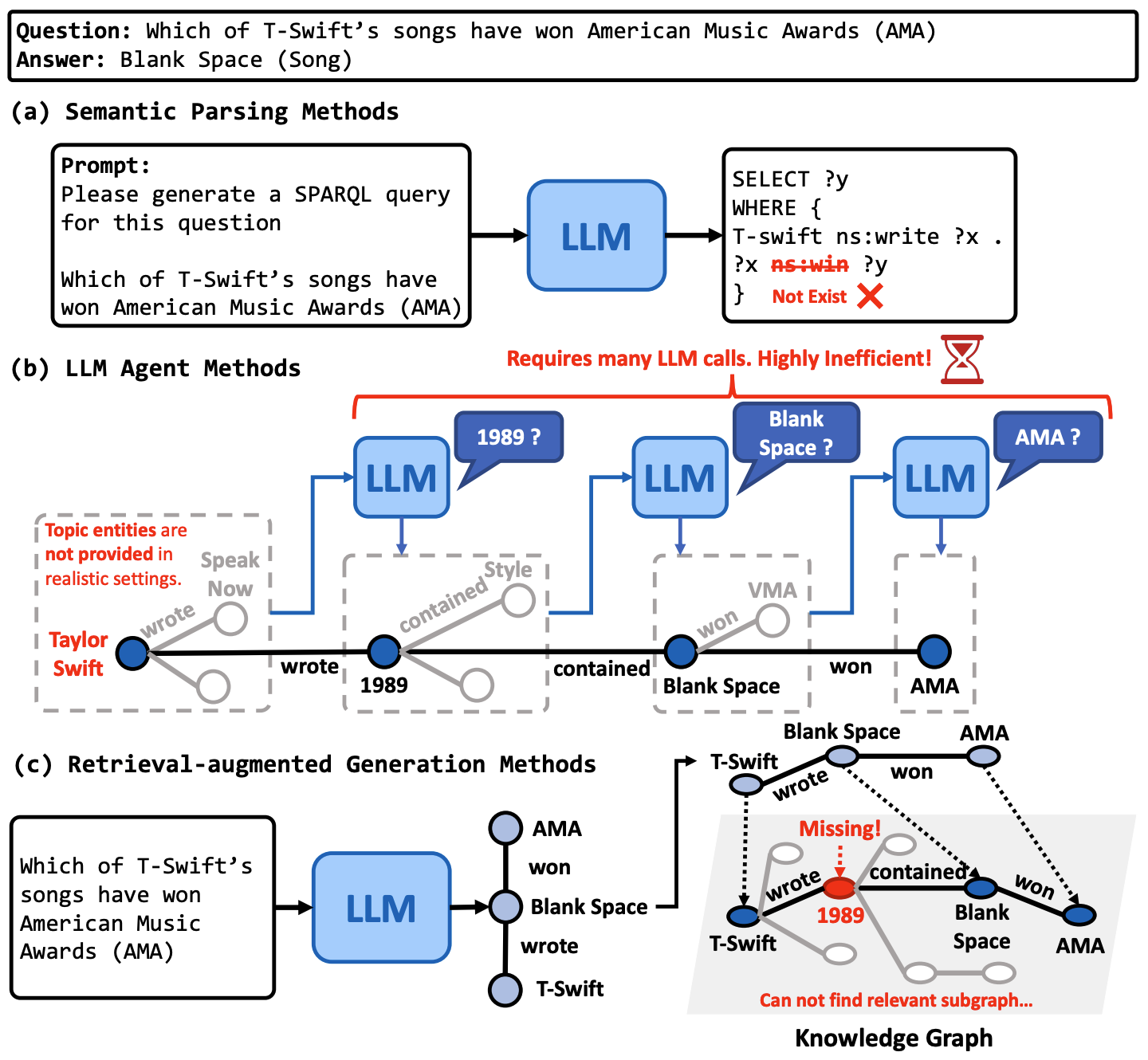
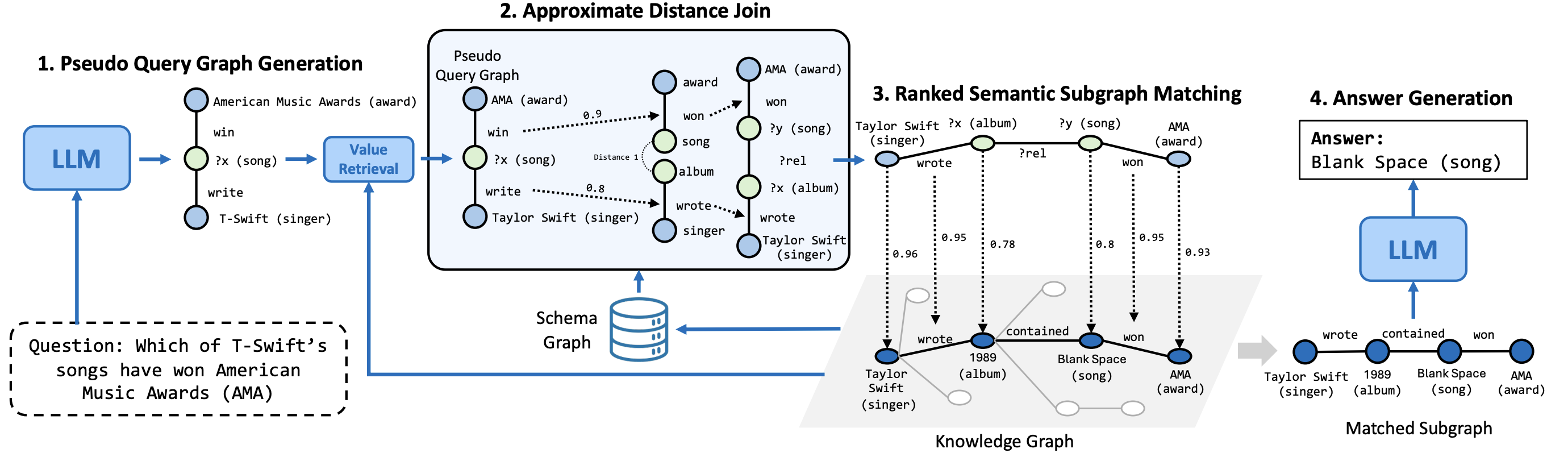
To reduce hallucinations in large language mod- els (LLMs), researchers are increasingly inves- tigating reasoning methods that integrate LLMs with external knowledge graphs (KGs). Exist- ing approaches either map an LLM-generated query graph onto the KG or let the LLM tra- verse the entire graph; the former is fragile because noisy query graphs derail retrieval, whereas the latter is inefficient due to entity- level reasoning over large graphs. In order to tackle these problems, we propose SAFE (Schema-Driven Approximate Distance Join For Efficient Knowledge Graph Querying), a framework that leverages schema graphs for robust query graph generation and efficient KG retrieval. SAFE introduces two key ideas: (1) an Approximate Distance Join (ADJ) al- gorithm that refines LLM-generated pseudo query graphs by flexibly aligning them with the KG’s structure; and (2) exploiting a compact schema graph to perform ADJ efficiently, reduc- ing overhead and improving retrieval accuracy. Extensive experiments on WebQSP, CWQ and GrailQA demonstrate that SAFE outperforms state-of-the-art methods in both accuracy and efficiency, providing a robust and scalable so- lution to overcome the inherent limitations of LLM-based knowledge retrieval.
Conference
📊ASM: Harmonizing Autoregressive Model, Sampling, and Multi-dimensional Statistics Merging for Cardinality Estimation
Kim, K., Lee, S., Kim, I., Han, W.
ACM SIGMOD, 2024.
▾
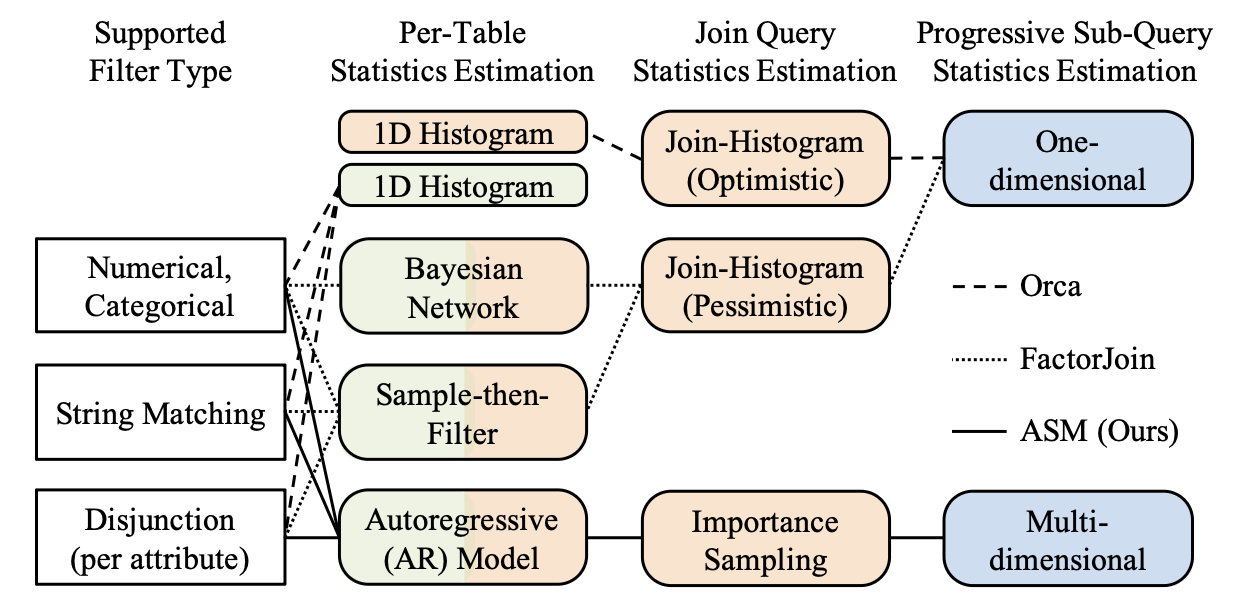
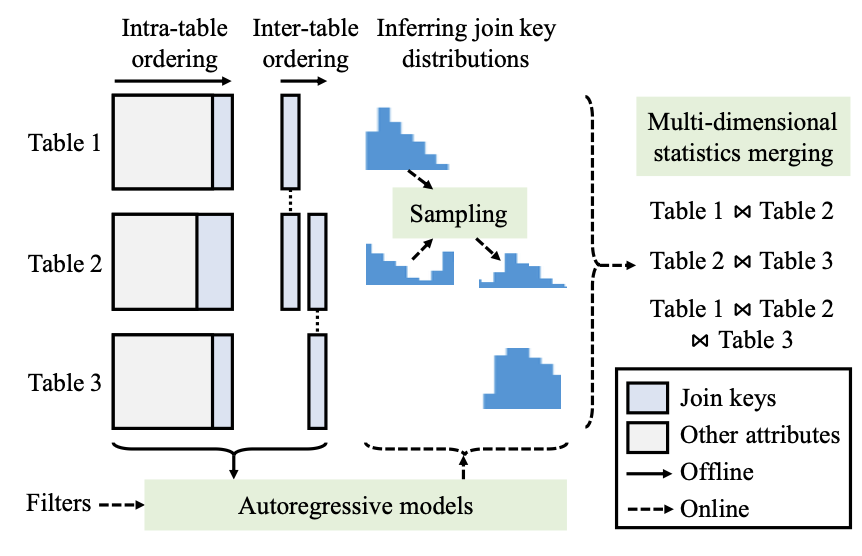
Recent efforts in learned cardinality estimation (CE) have substan- tially improved estimation accuracy and query plans inside query optimizers. However, achieving decent efficiency, scalability, and the support of a wide range of queries at the same time, has re- mained questionable. Rather than falling back to traditional ap- proaches to trade off one criterion with another, we present a new learned approach that achieves all these. Our method, called ASM, harmonizes autoregressive models for per-table statistics estima- tion, sampling for merging these statistics for join queries, and multi-dimensional statistics merging that extends the sampling for estimating thousands of sub-queries, without assuming indepen- dence between join keys. Extensive experiments show that ASM significantly improves query plans under a similar or smaller over- head than the previous learned methods and supports a wider range of queries.
Conference
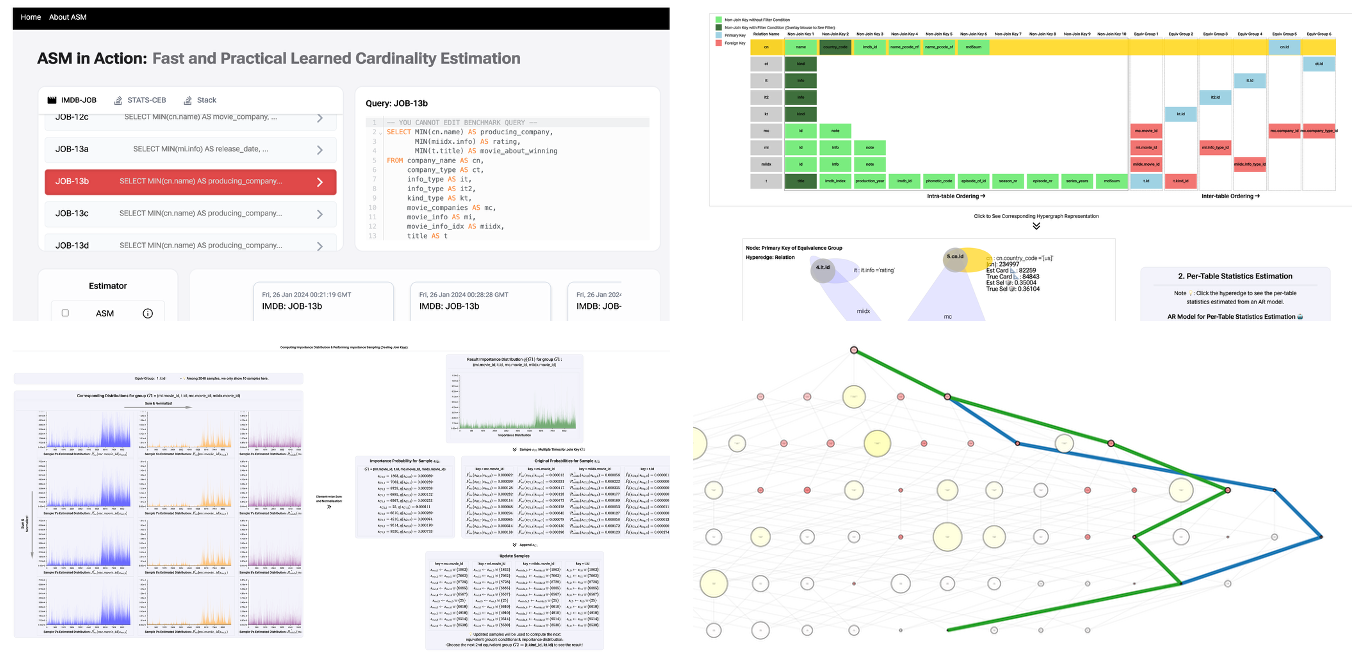
🎯ASM in Action: Fast and Practical Learned Cardinality Estimation
Lee, S., Kim, K., Han, W.
ACM SIGMOD Demonstration Proposals, 2024.
▾
Learned cardinality estimators have shown remarkable improvements in estimation accuracy by exploiting machine learning techniques, yet suffer from inefficiency or sub-optimal query plans when deployed in query optimizers. ASM is a new learned cardinality estimator that significantly outperformed previous approaches in terms of end-to-end execution times. This demonstration illustrates the internal estimation process of ASM that utilizes autoregressive models, sampling, and multi-dimensional statistics merging, and compares its performance with other alternatives. To do so, we visualize the detailed plan space exploration utilizing the estimation results. Please see youtube link for the demo video!